3. Erde
Wir konstruieren zunächst ein Bild unseres Flughafens, in dem wir die Daten sammeln, die wir zum Betrieb eines Flughafens benötigen. Dieser Prozess wird Modellierung genannt. Wir verwenden keine speziellen Verfahren, sondern konzentrieren uns auf die Umsetzung mittels SQL.
Da unser Flughafen auf der Erde liegen soll benötigen, wir ein Bild unserer Erde. Wir gehen wie in Abbildung 1 von einer Kugel aus und definieren für diese Längen- und Breitengrade. Dazu wählen wir eine Äquatorebene senkrecht zur Drehrichtung der Erde. Als Pole bezeichnen wir die Durchstoßpunkte der Drehachse. Wir wählen die Bezeichnungen Nord- und Südpol. Wir zählen Breitengrade als Winkel zwischen Drehachse und Äquatorebene in nördlicher Richtung positiv (90° Nordpol) und in südlicher negativ (-90° Südpol). Die Längengrade werden in östlicher Richtung gezählt, von 0° bis 360°.
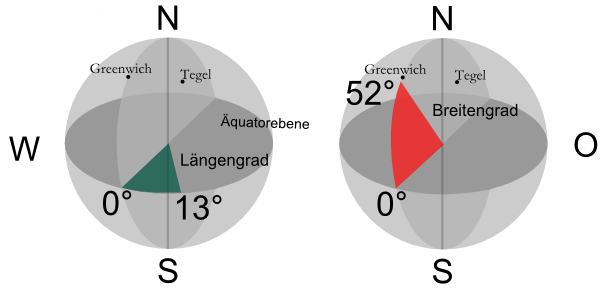
Die Definition von Breiten- (latitude) und Längengraden (longitude) erreichen
wir, in dem wir die Datentypen latitude und longitude anlegen. Dazu
verwenden wir den DDL-Befehl CREATE DOMAIN.
CREATE DOMAIN latitude float
CHECK (VALUE BETWEEN -90.0 AND 90.0);CREATE DOMAIN longitude float
CHECK (VALUE BETWEEN 0.0 AND 360.0);Beide Datentypen sind vom Basistyp float. Der Datentyp
float beschreibt eine Fließkommazahl. Der Wertebereich der
Datentypen geben wir jeweils durch eine CHECK-Integritätsbedingung an. Wir
fassen nun noch beide Datentypen in einem Datentypen zusammen, den wir
mittels des DDL-Befehls CREATE TYPE erstellen.
CREATE TYPE location AS (
latitude latitude,
longitude longitude
);Der Datentyp location ist aus den Komponenten mit den
Namen latitude und longitude zusammengesetzt. Als Datentypen der
jeweiligen Komponente verwenden wir die gleichnamige Domain. Wir verwenden
Domainen, da die Typdefinition keine CHECK-Bedingung bietet. Wir
überprüfen die Eigenschaften des Datentyps location durch den
DML-Befehl SELECT.
SELECT '(90.0, 360.0)'::location;
location
----------
(90,360)
(1 row) Dem Befehl SELECT folgt eine nicht typisierte
Zeichenkette. Der doppelte Doppelpunkt konvertiert die Zeichenkette,
begrenzt durch eingestrichene Anführungszeichen, in den Datentypen
location. Diese Form der Umwandlung wird explizit genannt, da
der Zieldatentyp, location, angegeben ist. Bei impliziten
Umwandlungen ergibt sich z.B. der Datentyp aus dem Datentyp des
Datenbankfeldes, in das ein Wert eingefügt werden soll. Die Zeichenkette
wird als Liste interpretiert. Der erste Wert wird entsprechend der
Definition des zusammengesetzten Datentyps location in die
Komponente latitude, der zweite in die Komponente longitude aufgenommen.
SQL-Anweisungen werden stets durch ein Semikolon abgeschlossen. Wir
überprüfen nun die Festlegung der Wertebereiche durch Verletzung einer
CHECK-Integritätsbedingung.
SELECT '(90.1, 0.0)'::location;
FEHLER: Wert für Domäne latitude verletzt Check-Constraint »latitude_check«Offensichtlich ist die Integritätsbedingung für die Komponente latitude verletzt. Zur Maskierung von Anführungszeichen in Zeichenketten verwenden wir das Anführungszeichen zweimal.
SELECT 'Zeichenkette mit maskiertem ''-Zeichen';
?column?
---------------------------------------
Zeichenkette mit maskiertem '-Zeichen
(1 row)Zur Verbindung von Zeichenketten untereinander verwenden wir den Verbindungsoperator ||.
SELECT 'erste Zeichenkette '||'zweite Zeichenkette';
?column?
----------------------------------------
erste Zeichenkette zweite Zeichenkette
(1 row)Der Verbindungsoperator ist für viele Datentypen definiert. So können wir z.B. ein Feld ganzer Zahlen um eine weitere Zahl damit ergänzen.
SELECT '{1,2,3,4,5,6}'::integer[] || 7::integer;
?column?
-----------------
{1,2,3,4,5,6,7}
(1 row)Die zunächst nicht typisierte Zeichenkette wird in ein Feld, [], von ganzen Zahlen umgewandelt und anschließend um die einzelne, ganze Zahl erweitert. Die doppelten Anführungszeichen verwenden wir um Namen anzugeben, die nicht ohne weiteres dem SQL-Standard entsprechen. Im Folgenden wird das Schlüsselwort SELECT als Bezeichner für die aktuelle Datumsangabe genutzt.
SELECT now() as "SELECT";
SELECT
----------------------------
2011-04-27 15:59:05.433+02
(1 row)Kommentare für eine Zeile werden durch -- eingeleitet, mehrzeilige mit /* und */ begrenzt.
-- einzeiliger Kommentar endet am Zeilenende
/* mehrzeiliger
Kommentar */Da Flüge häufig international sind, unterteilen wir die Erde in Länder. Die Speicherung von Datensätzen erfolgt in relationalen Datenbanksystemen durch Tabellen. Tabellen bestehen aus einer Menge von Zeilen. Jede Zeile besteht aus einer Reihe von Feldern, in die Daten eines Datensatzes eingetragen werden können. Vor Nutzung einer Tabelle muss diese zunächst erzeugt werden.
CREATE TABLE countries (
country_id char(2),
name varchar(256) NOT NULL,
population integer
);Der DDL-Befehl CREATE TABLE erzeugt die Tabelle
countries. Die Länder besitzen einen zweistelligen, eindeutigen Ländercode
und einen Namen, der bis zu 256 Zeichen umfassen kann. Zudem wird die
Bevölkerungszahl als ganze Zahl erhoben. Um diese Eigenschaften zu
speichern werden Felder definiert. Ein Feld wird mindestens durch einen
Namen und einen Datentyp beschrieben.
Über den DML-Befehl INSERT INTO fügen wir nun
Datensätze, die Länder repräsentieren, zwecks Speicherung in die Tabelle
countries ein.
INSERT INTO countries (country_id, name) VALUES ('AU', 'Australia');
INSERT INTO countries (country_id, name) VALUES ('AT', 'Austria');
INSERT INTO countries (country_id, name) VALUES ('CH', 'Switzerland');
INSERT INTO countries (country_id, name) VALUES ('DE', 'Germany');
INSERT INTO countries (country_id, name) VALUES ('ES', 'Spain');
INSERT INTO countries (country_id, name) VALUES ('US', 'United States');Nach dem Befehl INSERT INTO folgt der Name der
Tabelle, countries. In der Folgenden Liste werden die Felder genannt, in
die Werte eingefügt werden sollen. In diese Felder wird der Wert aus der
Liste nach dem Schlüsselwort VALUES gespeichert, der in der Liste an der
gleichen Position wie der Name des Feldes steht. Pro Anweisung wird eine
Zeile, die einen Datensatz aufnimmt, in die Tabelle eingefügt. In alle
Felder, für die kein Wert eingefügt wird, wird entweder ein
Initialisierungswert (Default) oder der Wert NULL für undefiniert
eingefügt. Die Konvertierung der nicht typisierten Zeichenketten aus den
INSERT-Anweisungen geschieht implizit. Um das Einfügen zu überprüfen
fragen wir nun alle Datensätze aus der Tabelle countries ab.
SELECT * FROM countries;
country_id | name | population
------------+---------------+------------
AU | Australia | NULL
AT | Austria | NULL
CH | Switzerland | NULL
DE | Germany | NULL
ES | Spain | NULL
US | United States | NULL
(6 rows)Dies erreichen wir durch Verwendung des DML-Befehls
SELECT. Der Stern-Operator wählt alle Felder aus. Dem
Schlüsselwort FROM folgt hier der Name der Tabelle, aus denen Datensätze
abgefragt werden sollen. Wie wir sehen ist zu jedem Datensatz ein
Ländercode, country_id, gegeben. Jeder Ländercode kommt zudem nur einmal
vor.
Da jede Tabelle theoretisch einen Primärschlüssel enthalten muss,
der einen Datensatz eineindeutig ausweist, vereinbaren wir das Feld
country_id nun als Primärschlüssel der Tabelle. Dazu fügen wir die
folgende Integritätsbedingung mittels des DDL-Befehls ALTER
TABLE der Tabelle countries hinzu.
ALTER TABLE countries ADD CONSTRAINT pk_country_id PRIMARY KEY (country_id);Das Schlüsselwort PRIMARY KEY weist das Feld country_id
nun als Primärschlüssel aus. Die Werte eines Primärschlüssels sind immer
definiert und eindeutig. Die Anzahl der Elemente der Menge der
Primärschlüssel entspricht also der Anzahl der Datensätze. Würden wir
einen weiteren Datensatz mit einem schon vorhandenen Ländercode einfügen
wollen, würde diese Anweisung als Fehler zurückgewiesen. Offensichtlich
ist im Folgenden die Integritätsbedingung pk_country verletzt
INSERT INTO countries (country_id, name) VALUES ('US', 'United States');
FEHLER: doppelter Schlüsselwert verletzt Unique-Constkraint »pk_country_id«
DETAIL: Schlüssel »(country_id)=(US)« existiert bereits.Die NOT NULL-Bedingung in der Definition des Feld name ist dagegen
optional. Sie erzwingt stets die Angabe eines Namens. Würde statt dessen
der Datenbankwert NULL, so würde die Datenbankoperation als fehlerhaft
zurückgewiesen. Um dies zu überprüfen fügen wir einen Datensatz mittels
des DDL-Befehls INSERT INTO in die Tabelle countries
ein. Offensichtlich ist im Folgenden die Integritätsbedingung NOT NULL für
das Feld Name verletzt.
INSERT INTO countries (country_id, name) VALUES ('DE', NULL);
FEHLER: NULL-Wert in Spalte »name« verletzt Not-Null-ConstraintFür die Bevölkerungszahl wird in der SELECT-Anweisung oben stets ein
NULL-Wert ausgegeben, da beim Einfügen der Datensätze keine Angaben über
die Bevölkerung mit aufgenommen wurden. Um dies nachzuholen verändern wir
die Datensätze mit dem DML-Befehl UPDATE
UPDATE countries SET population = 80000000 WHERE country_id = 'DE';Diese Anweisung setzt die Bevölkerungszahl für die Datensätze auf 80000000, die die WHERE-Bedingung erfüllen. In diesem Fall wird der Ländercode von Deutschland gefordert. Wir betrachten das Ergebnis.
SELECT * FROM countries;
country_id | name | population
------------+---------------+------------
AU | Australia | NULL
AT | Austria | NULL
CH | Switzerland | NULL
ES | Spain | NULL
US | United States | NULL
DE | Germany | 80000000
(6 rows)Wie wir sehen wird der veränderte Datensatz als letztes ausgegeben und enthält den Wert der UPDATE-Anweisung. Die Veränderung der Ausgabeposition liegt an der Speicherung des Datensatzes innerhalb des Datenbanksystems PostgreSQL. Intern wurde ein Tupel, das den neuen Datensatz für DE enthält, an die Liste der bestehenden Tupel einer Tabelle angehängt. Das Tupel, das vorher den aktuellen Wert des Datensatzes darstellte, wurde als veraltet markiert. Diese Eigenschaft von PostgreSQL legt die Verwendung eines Sortierverfahrens vor Ausgabe der Datensätze nahe.
Die Daten oder Tupel einer Tabelle werden jeweils in Datenbankblöcken der Größe 8kb (Vorzugswert) gespeichert. Für eine UPDATE-Anweisung wird das Tupel bestenfalls in dem gleichen Datenbankblock gespeichert, in dem der Datensatz zunächst eingefügt wurde. Überschreitet die durch INSERT- und UPDATE-Anweisungen hinzu gespeicherte Menge von Daten die Größe eines Datenbankblockes, so wird ein neuer Datenbankblock erzeugt.
SHOW block_size;
block_size
------------
8192
(1 row)Zum Löschen eines Datensatzes wird das dazugehörige Tupel zunächst als veraltet markiert. Die veralteten Tupel können durch einen VACUUM-Befehl entfernt werden.
VACUUM VERBOSE COUNTRIES;Zunächst ergänzen wir die Bevölkerungszahlen für die anderen Länder, bis auf den Datensatz der Schweiz.
UPDATE countries SET population = 21000000 WHERE country_id = 'AU';
UPDATE countries SET population = 8000000 WHERE country_id = 'AT';
UPDATE countries SET population = 40000000 WHERE country_id = 'ES';
UPDATE countries SET population = 300000000 WHERE country_id = 'US';Wir betrachten nun die Länder nach der Bevölkerungszahl. Die Länder sollen nach der Bevölkerungszahl abnehmend aufgeführt werden.
SELECT * FROM countries ORDER BY population DESC;
country_id | name | population
------------+---------------+------------
CH | Switzerland | NULL
US | United States | 300000000
DE | Germany | 80000000
ES | Spain | 40000000
AU | Australia | 21000000
AT | Austria | 8000000
(6 rows)Zur Sortierung der Datensätze verwenden wir die ORDER BY-Bedingung. Im Beispiel oben geben wir das Feld population als Sortierkriterium an. Der Zusatz DESC (descendending) bedingt eine absteigende Sortierung. Die Angabe ASC (ascendending) ordnet die Datensätze dagegen aufsteigend. Wie wir sehen wird der Datensatz für die Schweiz an erster Stelle aufgeführt. Wir können diesen Datensatz ausschließen, indem wir die SELECT-Anweisung mit einer WHERE-Bedingung verfeinern.
SELECT * FROM countries WHERE country_id <> 'CH' ORDER BY population DESC;
country_id | name | population
------------+---------------+------------
US | United States | 300000000
DE | Germany | 80000000
ES | Spain | 40000000
AU | Australia | 21000000
AT | Austria | 8000000
(5 rows)Die WHERE-Bedingung fordert hier einen Ländercode ungleich dem der
Schweiz. Wir können aber auch den Datensatz mittels des DDL-Befehls
DELETE für die Schweiz löschen.
DELETE FROM countries WHERE country_id = 'CH';Hier sorgt die WHERE-Bedingung für die Auswahl des Datensatzes der Schweiz. Alternativ könnten wir alle Datensätze löschen, deren Bevölkerungszahl den Wert NULL aufweisen. Davon wäre allein der Datensatz der Schweiz betroffen.
DELETE FROM countries WHERE population IS NULL;Anstelle des Vergleichsoperators = wird zum Auffinden von
NULL-Werten der Ausdruck IS NULL oder invers IS NOT
NULL für alle nicht NULL-Werte verwendet. Wir wollen nun die
Differenz zwischen allen Datensätzen und denen, deren Bevölkerungszahl den
Wert NULL aufweist, ermitteln. Gelöschte Datensätze werden in PostgreSQL
zunächst nicht pyhsikalisch gelöscht. Sie werden zunächst nur markiert.
Erst durch Anwendung des VACUUM-Befehls werden sie
physikalisch gelöscht.
SELECT count(*) - count(population) FROM countries;
?column?
----------
0
(1 row)Die Aggregat-Funktion count mit dem Argument * zählt alle Zeilen,
Datensätze, der Tabelle countries, während mit dem Argument population
alle Datensätze gezählt werden, für die der Wert von population ungleich
NULL ist. Da die Differenz 0 ist, können wir nun fordern, dass die
Bevölkerungszahl stets einen Wert ungleich NULL hat. Dazu erweitern wir
die Definition des Feldes population in der Tabelle countries um eine NOT
NULL-Bedingung. Wir verwenden den DDL-Befehl ALTER
TABLE.
ALTER TABLE countries ALTER population SET NOT NULL;Wir überprüfen die Wirkung der NOT NULL-Bedingug, in dem wir den Datensatz der Schweiz erneut einfügen.
INSERT INTO countries (country_id, name) VALUES ('CH', 'Switzerland');
FEHLER: NULL-Wert in Spalte »population« verletzt Not-Null-ConstraintDie Ausdrücke der oben benutzten WHERE-Bedingungen werden jeweils zu einem Wahrheitswert hin ausgewertet. Teilsausdrücke können mittels der Boolschen Algebra miteinander verknüpft werden. Neben Und (AND)- und Oder (OR)-Verknüpfungen ist die Verwendung von Klammern erlaubt. Erst wenn der gesamte Ausdruck wahr ist, wird der Datensatz in die Ergebnismenge aufgenommen. Die WHERE-Bedingung wirkt als Filter auf die gelesenen Datensätze einer Tabelle.
SELECT *
FROM countries
WHERE ( country_id IN ('DE', 'ES') AND population > 40000000 )
OR name LIKE 'United%';
country_id | name | population
------------+---------------+------------
DE | Germany | 80000000
US | United States | 300000000
(2 rows)In der SELECT-Anweisung oben ist der Ausdruck der WHERE-Bedingung
dann wahr, wenn entweder der Name des Landes mit der Zeichenkette United
beginnt oder die Länderkennung in der Menge der Länderkennungen von
Deutschland und Spanien enthalten ist sowie die Bevölkerungszahl größer
40000000 ist. Der Bereichsoperator IN verweist den Wert der country_id auf
die Aufzählung der Ländercodes. Die AND-Verknüpfung fordert, dass
gleichzeitig die Einwohnerzahl des Landes größer als 40000000 ist. Beides
zusammen trifft lediglich auf Deutschland zu. Die Klammern gruppieren
beide Teilausdrücke. Der Ausdruck name LIKE 'United%' passt
auf alle Ländernamen, die mit United beginnen und beliebig fortgesetzt
werden oder nicht. Das Prozentzeichen agiert hier als sogenanntes don't
care.